HoME
HoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou
组织:快手
核心问题:
专家崩溃
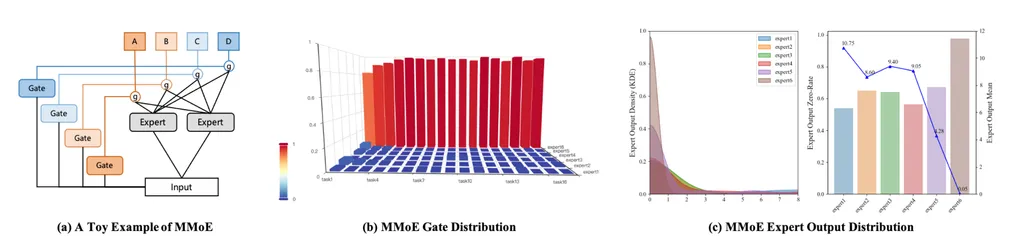
- 背景:MMoE结构
- 现象:所有的上游Tower,对专家的权重几乎都集中在6号专家上
- 原因分析:打印出专家输出的score,发现1-5号专家的分数值域相近,6号专家的值域约为其他专家的1/1
- 思考:
- 分数差异大&weights差异大,最后其实每个专家贡献可能又拉近回去了?
- 分数差异大是原因还是结果?是weights先不均衡导致expert更新变差,还是expert值域不均衡导致weights分布不均衡?
- 解决方案:
专家退化
- 背景:解决完专家崩溃问题后,基线升级为CGC
- 现象:共享专家退化成仅对特定几个任务有较大贡献,对多数任务无贡献
- 原因分析:
- 思考:同上述问题,“贡献”和“值域”是有反比关系的,仅分析weights、不分析值域的话,是否能说明问题客观存在?
- 解决方案:
专家欠拟合
- 背景:解决专家退化问题,共享专家在各任务上均有可观权重
- 现象:部分任务的私有专家权重很小,仅分配权重在共享专家上
- 原因分析:不同任务的label的稀疏性不一样(最大的差100倍),私有专家更新不如共享专家频繁,导致私有专家权重较小?
- 思考:还是要结合值域分析,才能确定问题
- 解决方案:
核心贡献
Expert normalization&Swish mechanism
- 目的:解决专家崩溃问题
- 方法:
- 将专家的输出标准化到标准正态分布。(对每个专家单独使用BN)
- 在此基础上,继续使用ReLU会导致output陷入0的比例非常多,因此使用Swish作为激活函数,将ReLU替换为Swish。
- 思考:使用BN之后的输出不是N(0,1)而是N(beta,gamma^2),为什么说能够拉近专家的值域?和我犯的一样的错误?以及,在这样的操作之后,自然Swish的使用也是说不上道理的
Hierarchy mask mechanism
- 目的:减少专家占用问题,避免专家退化(也称作任务冲突跷跷板)
- 方法:将相似的任务分到一个group,共享专家分为全局共享专家和group内的共享专家。
- 思考:这里是将专家退化直接认为是任务冲突负迁移跷跷板的结果?
Feature-gate and Self-gate mechanisms
- 目的:减轻多任务稀疏度不同对模型训练的影响,解决专家欠拟合问题
- 方法:
- Feature-gate:
- Self-gate:
- 思考: